[ Video version here. ]
My first job was as a machine learning researcher in a product group at one of the big tech companies.
I remember thinking I needed a backup plan, because I was pretty sure the whole machine learning thing would turn out to be a fad, and then I’d have to figure out if I wanted to be a software engineer or a program manager…or if I’d just try to move back in with mom and dad.
A few years later I started managing other machine learning researchers. Every year at review time I encouraged them to keep up their non-machine learning skills. You know, because of the whole ‘machine learning might be a fad’ thing…
Boy was I wrong. Today machine learning is more than just a single stable career path, there are actually many different types of careers you can have in machine learning, depending on your interests and skills.
For example, my titles have included: researcher, applied researcher, program manager, applied research manager, principal software engineer, architect, machine learning scientist, and software engineering manager. And over the past 15 years I’ve worked with: data scientists, decision scientists, data analyst, machine learning engineers, data quality engineers, scientists, applied scientists, research scientists, and ranking engineers. And all of these titles were doing similar data and ML focused work.
So what the heck is going on?
Well, the large scale use of data is relatively new and we’re inventing stuff as we go. Different organizations have different data cultures, and there are many strange evolutionary forces at work.
For example, one company I worked for got rid of the ‘software test engineer’ function. In the process, many software test engineers were given the option to change their titles ‘data scientist’…and then to try to figure out what the heck a data scientist did for a living…
As you can imagine, this led to some chaos. And it strongly affected the data culture at the company. Because everyone who was a data scientist before this change did everything they could to avoid getting sucked into management chains that had no data experience, but huge data ambition.
The result? If you’re looking for a job at this company and search for ‘data science’ you might not end up with what you expect.
Another company I worked for thinks data skills will consolidate over time and eventually every software engineer will add ‘data and ML’ to their toolkit…and there won’t be any specialized data people…eventually. So if you search for ‘data scientist’ at this company you might find nothing – but the company would love to hire people with strong data science skills as ‘engineers’.
I’m sure there are hundreds of similar stories across the industry. And as people who learn data in one culture move between companies, things are diffusing and blending in crazy ways.
The point is: when you’re looking for a job in data or machine learning, keep an open mind – don’t get over-indexed on a particular title or a particular way of looking at the field.
So where to start? Here are five data professional job functions that I think will become stable over time. The names may vary, but the functions (hopefully) won’t. These are:
- Machine Learning Researcher
- Data Scientist
- Machine Learning Scientist (Modeler)
- Machine Learning Engineer
- Machine Learning Architect (Program Manager)
Keep in mind that these are functions, not jobs. Most jobs will blend these to various degrees. I’ll go through and give a bit more detail.
Machine Learning Researcher
Machine Learning Researchers advance the state of human knowledge. They come up with theories about how the world works and they create experiments to test those theories. When they are right, the result is new algorithms or approaches that allow us to accomplish more than we thought we could.
And it is an exciting time to be a researcher in machine learning. Things are advancing crazy fast and small groups of people have accomplished incredible things.
Machine Learning researchers might be ‘applied’ in that they work in the context of a specific product, like a search engine or a self-driving car. But fundamentally research is not about building products. It is about understanding why a particular approach works in a particular setting, and creating knowledge that transcends any single feature or product.
Core skills for success with machine learning research include: scientific method, ability to deal with ambiguity, a high level of comfort with advanced math, good communication, the ability to advocate for crazy ideas, and just enough engineering skills to carry out some experiments.
To become a professional Machine Learning Researcher – like to get some company to sponsor you to sit around and try to advance human knowledge – you really need to publish papers at top scientific conferences. And the only practical way to learn how to do that is to get a PhD in Machine Learning.
There was a time when the only way to learn machine learning was to get a PhD; so there was a time where just about every professional machine learning practitioner had a PhD. But this is no longer necessary. In fact, unless you really want to advance human knowledge and write papers: a PhD is an inefficient way to become a data professional.
Data Scientist
Data Scientists find the stories in data and share them with others. They explore large data sets and answer questions, measure performance, track down problems, and find unexpected connections. A great data scientist is like a detective – they know how to interpret the clues they find in the data and track those clues to uncover valuable insights.
Most data scientists have background in statistics or applied mathematics, coupled with enough programming skill to independently get at log data, process and clean it, query it, and automate repetitive tasks.
And data science requires a specific mentality. You have to like staring at data and dreaming up stories that explain it. But you also have to be meticulous and technical enough to prove or disprove your stories (before spouting off random theories and confusing everyone around you).
Core skills for success with data science include: A curious and flexible mind, deep statistical knowledge, familiarity with data querying languages, and moderate programming, probably in R or Python.
And what does this have to do with machine learning?
You might say that Data Science is about understanding what is happening in a big complicated system, while “machine learning” is about predicting what is going to happen in the future. There is a lot of overlap in tools and approaches. The differences are about the focus.
Machine Learning Scientist (Modeler)
Machine Learning Scientists build models. They find or create training data, do feature engineering, they know what learning algorithm to use for any particular task, they tune model parameters, they measure, measure, measure, and they know how to evaluate the output of modeling runs and what to change to make based on these observations.
Modeling is an open ended, exploratory task. Kind of like constantly debugging a program written in a language you can’t understand. A machine learning scientist might spend weeks or months working on a single modeling task, making the model just a little bit better every single day.
Core skills for success at machine learning science include: a deep intuition with the core modeling algorithms and approaches, expertise in one or more domains (like NLP or computer vision), strong programming in a language like python, a lot of comfort with data processing and querying, and a passion for measuring and debugging.
The best way to become a machine learning scientist is to get a degree in a field with a computational focus, like computer science, applied math, maybe statistics or even a hard science like physics or chemistry. This will give the core statistics and computation skills. And then go to Kaggle.com and start entering their modeling competitions. Start doing well in Kaggle, and you’re well on your way to becoming a machine learning scientist.
Machine Learning Engineer
Machine Learning Engineers integrate machine learning into working systems to produce successful end-to-end experiences. They implement the runtimes where models execute, they build systems to deploy new models reliably, they connect model output into user experiences, and they build systems that collect telemetry about interactions between users and models, producing future training data.
Machine learning engineers create the systems that put guardrails around the machine learning modeling process, allowing creative exploration, but providing simple, reliable ways to take the resulting models and ingest them into the broader system.
Core skills for success in machine learning engineering start, of course, with a strong software engineering base. Beyond that, a good conceptual understanding of machine learning is key. Not the math behind the algorithms – that’s not super important to a machine learning engineer – but the pieces that make up a machine learning implementation, and where in the system should they live.
With a little study, any software engineer can get into machine learning engineering. You could take an online course, do a few Kaggle tutorials. But in my opinion, the best place to start is by reading this book. Building Intelligent Systems. Which I wrote. This book has all the stuff I wish I knew when I got started doing machine learning professionally.
Machine Learning Architect / Program Manager
Machine learning architects / program managers design ML-based solutions to real world problems. They know when machine learning is the right tool (and when it isn’t); they understand how to optimize a system end to end so that the machine learning is in position to shine; they know how to design around the mistakes that machine learning is guaranteed to make; and they know how to nurture a machine learning system through its lifecycle from a technical demo, to a viable product, to a world class solution.
When machine learning architects look at a problem they don’t ask: can my organization model that. They ask: should my organization model that. And if so what’s the best approach to be efficient and reliable. You can learn more by watching this video or this blog post.
Core skills for a machine learning architect or program manager are strong software design skills, customer empathy, and a strong conceptual understanding of aspects of machine learning (but not the math and not the specific algorithms).
And the best way to get into machine learning architecture or program management? Work as a program manager or engineer for a while… and then read Building Intelligent Systems. I don’t know. I’m sorry. I guess I’m a bit biased.
Summary
It’s an exciting time to be a data professional. Data and machine learning are making the world a better place – and things are changing fast. Good luck. Stay safe!
| ML Career | Core Activity | Core Skills |
| Machine Learning Researcher | Advance human knowledge | Scientific method, math, basic programming |
| Data Scientist | Stories from data | Statistics, data manipulation, communication |
| (Applied) Machine Learning Scientist | Build predictive models | Machine learning algorithms, domain specific feature engineering, basic programming |
| Machine Learning Engineer | Integrate machine learning into systems | Software engineering, conceptual machine learning |
| Machine Learning Architecture / Program Manager | Design solutions that leverage machine learning | Software design skills, customer empathy, Strong conceptual machine learning |

 Well, you might be machine learning the wrong thing…
Well, you might be machine learning the wrong thing…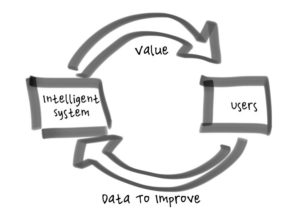 Closing the loop is about creating a virtuous cycle between the intelligence of a system and the usage of the system. As the intelligence gets better, users get more benefit from the system (and presumably use it more) and as more users use the system, they generate more data to make the intelligence better.
Closing the loop is about creating a virtuous cycle between the intelligence of a system and the usage of the system. As the intelligence gets better, users get more benefit from the system (and presumably use it more) and as more users use the system, they generate more data to make the intelligence better. Intelligent Systems make mistakes. There is no way around it. The mistakes will be inconvenient, some will be actually quite bad. If left unmitigated the mistakes can make an Intelligent System seem stupid, they could even render an Intelligent System useless or dangerous.
Intelligent Systems make mistakes. There is no way around it. The mistakes will be inconvenient, some will be actually quite bad. If left unmitigated the mistakes can make an Intelligent System seem stupid, they could even render an Intelligent System useless or dangerous. In my decade of managing applied machine learning teams I’ve interviewed maybe a hundred people. Over that time, I’ve come to rely on two main questions. I’m going to tell you what they are.
In my decade of managing applied machine learning teams I’ve interviewed maybe a hundred people. Over that time, I’ve come to rely on two main questions. I’m going to tell you what they are.